Units of Modulus of Elasticity (Young’s Modulus)
Before diving in to take a deeper look at the different types and units of modulus of elasticity (Young’s Modulus), let’s first take a look at a broad definition of this highly important mechanical property.

A basic definition of modulus of elasticity
Also known as elastic modulus, the modulus of elasticity is a measured value that represents a material’s resistance to elastic deformation, i.e., its ‘stretchiness’. It applies only to non-permanent deformation when under the effect of stress.
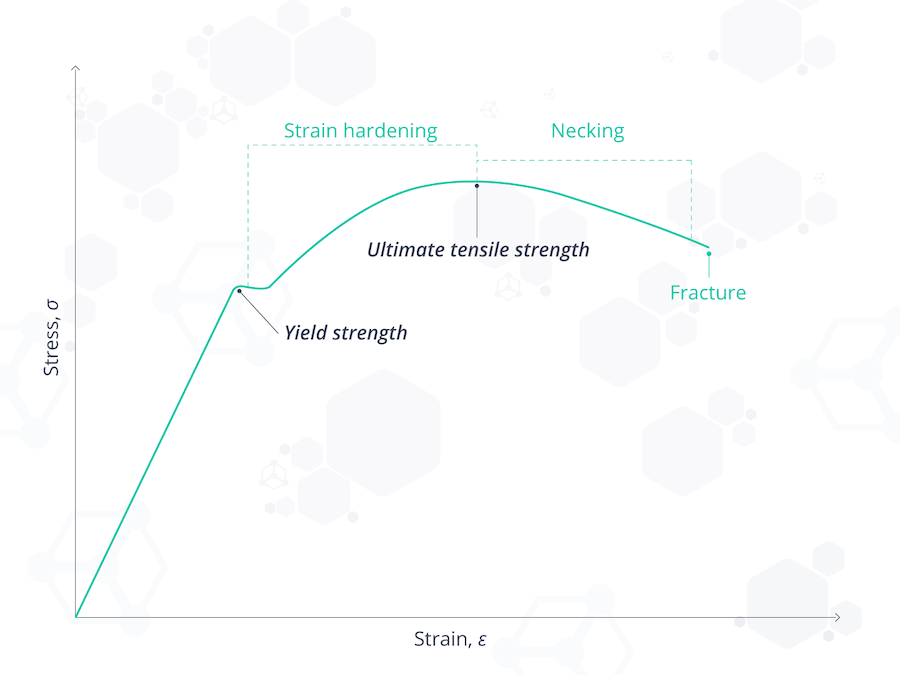
The modulus of elasticity is given by the gradient of the stress-strain curve in the region where it deforms elastically (see below – the linear section before “yield strength“). A less stretchy (or stiffer) material has a comparatively high modulus of elasticity, whereas a stretchy or springy substance has a lower one.
The elastic modulus is often represented by the Greek symbol lambda, λ. It takes the form of stress divided by strain, thus:
λ= stress/strain
- Stress is defined as the force that causes the deformation divided by the affected area.
- Strain is defined as the displacement of the particles of the substance relative to a specific length.
Types of modulus of elasticity
There are 3 main types of elastic modulus:
- Young’s modulus
- Shear modulus
- Bulk modulus
These are the elastic moduli most frequently used in engineering. Let’s take a look at each type and how they can be used before we get into the units of modulus of elasticity.
Young’s modulus
This is the one that most people are referring to when they say ‘elastic modulus’. It describes the amount a material deforms along a given axis when tensile forces are applied, also known as tensile elasticity. It can be described in simple terms as a measure of rigidity.
Young’s modulus can be simplified as the tendency of a substance to become longer and thinner.
It is defined as tensile stress divided by tensile strain (or the ratio of stress to strain) and is denoted as E in calculations.
The main application of Young’s modulus is to predict the extension that may occur under tension or the shortening that may occur under compression. This is useful when designing beams or columns in structural engineering, for instance.
Shear modulus
The shear modulus of a material is a measure of its stiffness. It is used when a force parallel to a given axis is met by an opposing force, such as friction. It can be simplified as the tendency of a substance to change from a rectangular shape to a parallelogram.
Shear modulus is defined as the ratio of shear stress to shear strain and is denoted by the symbols G, S or µ.
The shear modulus is most often used in calculations that involve two materials in contact and subject to opposing forces, i.e. rubbing together.
Bulk modulus
The bulk modulus is a thermodynamic property that is concerned with how resistant to compression a substance is. It can be simplified as the tendency of the volume of a substance to change, but the shape remaining the same.
It is defined as the ratio of pressure increase to relative volume decrease. It is denoted by the symbols K or B.
It is most often used when studying the properties of fluids under compression.

How is elastic modulus measured?
For this section, we are going to focus on Young’s modulus, as this is the one most commonly associated with elasticity.
The most common methods of measurement are the application of a tension test, bending test or natural frequency vibration test. Bending and tension testing methods rely on the application of Hooke’s law and are referred to as static methods. Using natural frequency provides a dynamic elastic modulus as the test is performed using vibrations.
The static methods are carried out by applying measurable parallel or perpendicular forces and recording the change in length or amount of deformation. Accurate devices that measure very small lengths are used, known as ‘extensometers‘ or mechanical strain gauges.
Units of modulus of elasticity
The units of modulus of elasticity are pressure units, as it is defined as stress (pressure units) divided by strain (dimensionless). Most commonly the units are Pascals (Pa) which is the SI unit, or pounds per square inch (psi) depending on the industry or geographical location. In Europe, Pa is most common, in the USA, psi is the more common unit of modulus of elasticity.
Some examples of values of the modulus of elasticity (Young’s modulus) of materials are as follows:
- Rubber has a low Young’s modulus of 0.01 to 0.1 GPa as it is highly elastic.
- Diamond has a high Young’s modulus of 1050-1200 GPa as it is highly rigid.
- Carbyne has the highest known Young’s modulus of 32100 GPa meaning it is the least elastic or most rigid material known at the moment.